Video Searching
This past weekend I created a small python program which can search through a collection of video files using natural (normal) language. The search will return the path of the video with the timestamp it thinks the described action is taking place.
For example, I indexed my local copy of The Office. From this point I was able to search something such as “people doing a fire walk” and it would return “S3E22 - Beach Games.mkv” with the timestamp of 1310s. If you want to verify this for yourself you can open your copy of The Office, Season 3, Episode 22, and fast forward to roughly 21:45 and you will see that they are doing the fire walk.
How does it work?
Embedding works by taking input data (like a sentence) and turning it to a vector. The model this project is using turns the data into vectors that are 2048 dimensions. For a short example however, we can look at 2 dimension vectors. Let’s say we have three sentences:
- “I like cars”
- “I love bikes”
- “Trash cans are black”
We (as humans) can tell that the first two sentences are similar, and the third is very dissimilar. But how do we let a computer know their similarity? This is what embedding does. It would turn the three sentences into vectors that might look like:
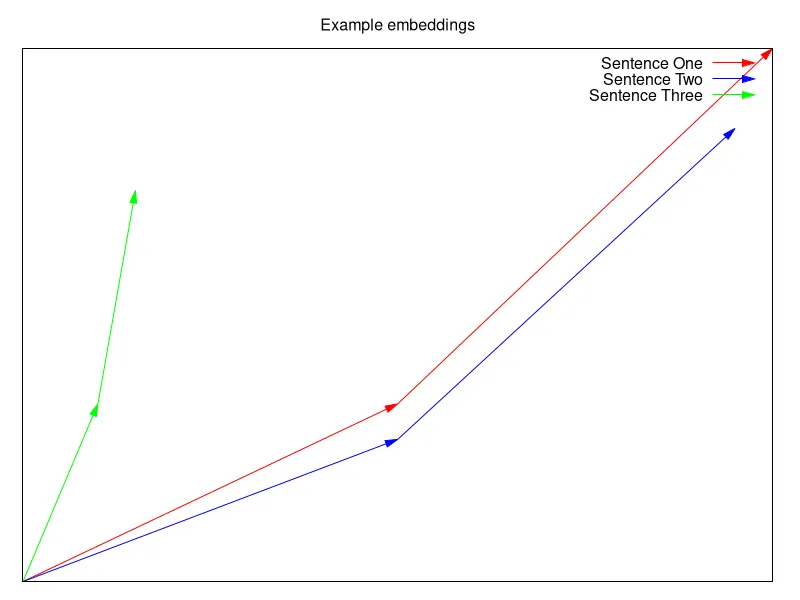
How the computer goes from data to vector is something I don’t know enough about to write about. So it will remain a black box for now.
In the image we can see that sentence one and two are close to each other, and sentence three is all by it’s self. Now, by computing the distance between the vectors we get a number that represents how similar the vectors (sentences) are.
By using a special embedding model, in this case Qwen3-VL-Embedding-2B, I can generate embeddings for video, images, and text. This is different from typical embedding models which can only embed videos or images or text. Instead of just being able to see the similarity of two sentences, we can now see the similarity of an image to a sentence.
Think; In the image above, red line could be an image, and the blue line could be a sentence.
So now we can see if a sentence is similar (representative) of a video.
For several reasons, we don’t want an embedding of the whole file though.
- The embedding would represent the entire movie/show, we want just one scene (or less)
- My hardware can’t embed that much information all at once, it’s not strong enough (not enough VRAM)
- The model doesn’t support that much data all at once
Because of these three reasons I split the video into 10 section chunks and embed each chunk, saving the result in a database alongside the file name, hash, and timestamp.
Now when the user wants to query all these video chunks, we just generate an embedding (get a vector representation of the search) and compute the distance to each video chunk’s embedding in the database. We then take the top few closest vectors, and return the corresponding file name and timestamp to the user.
Program Flow:
Indexing:
- Find all video files
- Break video files into 10s chunks
- Feed chunks into embedding model
- Save embedding vector with the file name and timestamp in a database
Searching (Querying):
- Embed the query using the same model
- Compute the distance from the query’s vector to each of the vectors in the database
- Return the data where the vectors were closest